Biomarkers Voice Clasifier App
 Voice Classification Demo App
Voice Classification Demo App
This project aim is to embeed a sound classification moden into simple android app for learning purposes. The model that classify 2-second audio samples is a small convolutional neural network. Sound classification is a machine learning task where you input some sound to a machine learning model to categorize it into predefined categories such as singing and speech. There are already many applications of sound classification.
Dataset
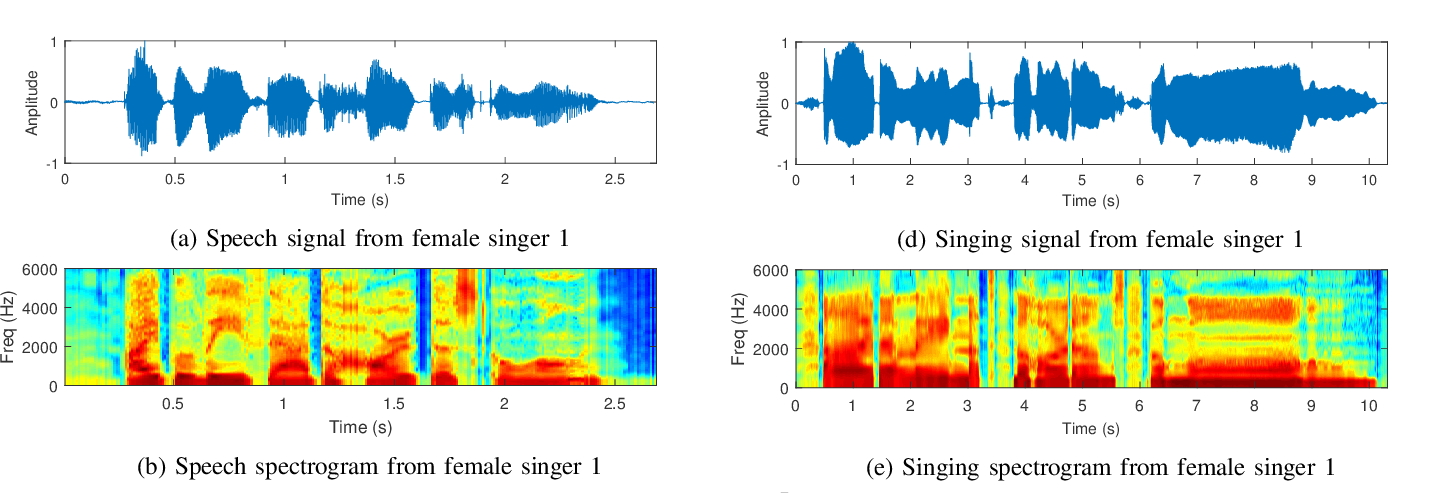
The first step to develop the model is to find a suitable dataset. For the siging database, the
NUS-48E Sung and Spoken Corpus developed at Sound and Music Computing Laboratory at National University of Singapore was used. The corpus is a 169-min collection of audio recordings of the sung and spoken lyrics of 48 (20 unique) English songs by 12 subjects and a complete set of transcriptions and duration annotations at the phone-level for all recordings of sung lyrics, comprising 25,474 phone instances.
The training datasetwas further pre-process by convert them to the WAV format and splitting them in 2 seconds window.
For the background samples, the dataset was complemented with the ESC-50 dataset. ESC-50 consist of a labeled collection of 2000 environmental audio recordings suitable for benchmarking methods of environmental sound classification. The dataset consists of 5-second-long recordings organized into 50 semantical classes (with 40 examples per class) loosely arranged into 5 major categories:
Model
The proof-of-concept model is just a basic 1D CNN model. The model receives a 1D time representation of sound. It first processes the time eries with successive layers of 2D convolution (Conv1D) bi-layers with ReLU activations.
The model ends in a number of dense (fully-connected) layers, which are interleaved with dropout layers for the purpose of reducing overfitting during training. The final output of the model is an array of probability scores, one for each class of sound the model is trained to recognize. The model was trained on Google Collab to take advantage of free GPU. For the integration into the app, the trained model was deployed with TensorFlow Lite.
App Deployment
Android sample app was the starting point to design the custom app. It enables to acquire the microphone data for over 2 seconds when tiping the record button.
References
[1] Gao, X., Sisman, B., Das, R., & Vijayan, K. (2018). NUS-HLT Spoken Lyrics and Singing (SLS) Corpus. 2018 International Conference on Orange Technologies (ICOT), 1-6.
Maria Monzon
Computer Vision and AI researcher
My research interests include Computer Vision, Biomedical Image Analysis, Trustworhty Deep Learning and Machine Learning for healthcare.